[DB] 데이터베이스 실행 계획에 대하여
- DB/Database Knowledge
- 2021. 6. 27.
실행 계획이란?
실행계획이란 사용자가 SQL을 실행하여 데이터를 추출하려고 할 때 옵티마이저가 수립하는 작업 절차입니다. 이렇게 만들어진 실행 계획은 여러 가지 방법을 통해 확인할 수 있습니다. 실제 프로젝트에서 SQL 튜닝 업무를 하다 보면 개발자들이 DBMS 툴을 활용하여 실행 계획을 확인하는 것을 자주 보실 수 있습니다. SQL을 실행한 후 실행 계획을 판단하여 이 SQL이 어떠한 방식으로 실행되는지 확인이 가능합니다.
[DB] 데이터베이스 옵티마이저(Optimizer)에 대하여
쿼리문의 실행 계획을 확인하는 방법
쿼리문의 실행 계획을 확인하는 방법은 EXPLAIN PLAN, AUTOTRACE, SQL TRACE 이렇게 3가지가 있습니다. 실행 계획을 판단하는 방법은 아래 포스팅에 오라클을 활용하여 방법과 예제를 자세히 기술할 테니 참고해주세요. 이 방법 외에도 DBMS 관리 툴을 활용하여 실행 계획을 확인하셔도 됩니다.
[Oracle] 오라클 실행 계획 확인하기 (EXPLAIN PLAN, SET AUTORACE, SQL TRACE)
실행 계획을 해석하는 방법
실행 계획은 여러 가지 단계로 이루어져 있는데 이것을 스텝이라고 합니다. 각각의 스텝에는 그 단계에서 어떤 명령이 수행되었고 총 몇 건의 데이터가 처리되었으며 이 처리를 위해 얼마만큼의 비용과 시간이 소요되었는지를 표시합니다.
실행 계획 순서 읽기
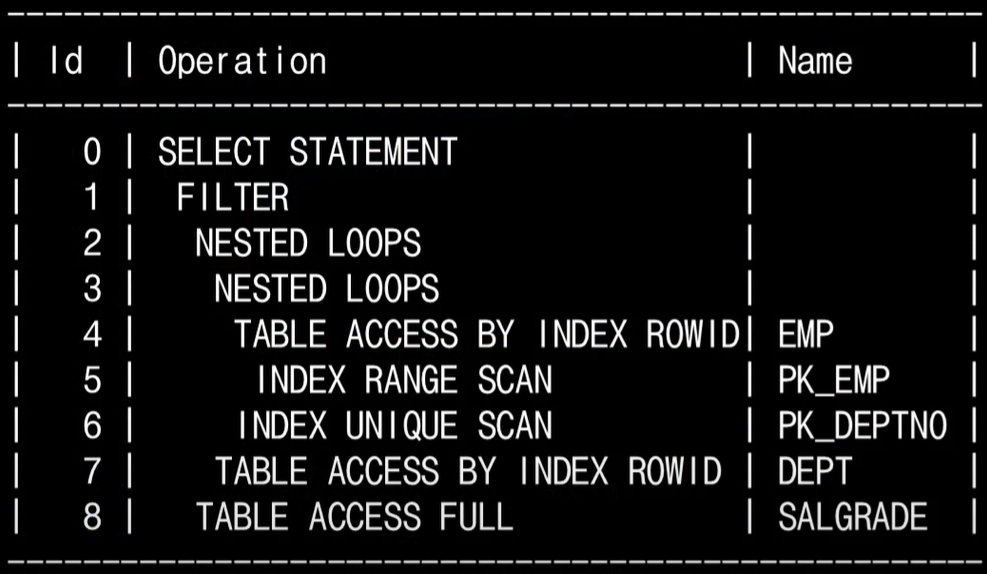
실행 계획을 읽을 때에는 아래와 같은 규칙이 있습니다. 이 규칙을 토대로 하나씩 읽어나갑니다.
1. 위에서 아래로 읽어 내려가면서 제일 먼저 읽을 스텝을 찾습니다.
2. 내려가는 과정에서 같은 들여 쓰기가 존재한다면 무조건 위 -> 아래 순으로 읽습니다.
3. 읽고자 하는 스텝보다 들여 쓰기가 된 하위스텝이 존재한다면, 가장 안쪽으로 들여쓰기 된 스텝을 시작으로 하여 한 단계씩 상위 스텝으로 읽어 나옵니다.

위의 예제의 경우 이 규칙으로 실행 계획을 읽는 순서를 정한다면 위와 같이 됩니다. 출력된 실행 계획에서 위쪽에 출력된 결과일수록(ID 칼럼의 값이 작을수록) 쿼리의 바깥(Outer) 부분이거나 먼저 접근한 테이블이고, 아래쪽에 출력된 결과일수록(ID 칼럼의 값이 클수록) 쿼리의 안쪽(Inner) 부분 또는 나중에 접근한 테이블에 해당됩니다.
실행 계획 해석하기
실행 계획의 해석 가장 나중에 실행된것부터 즉 트리의 가장 좌측 아래부터 역순으로 해석합니다.
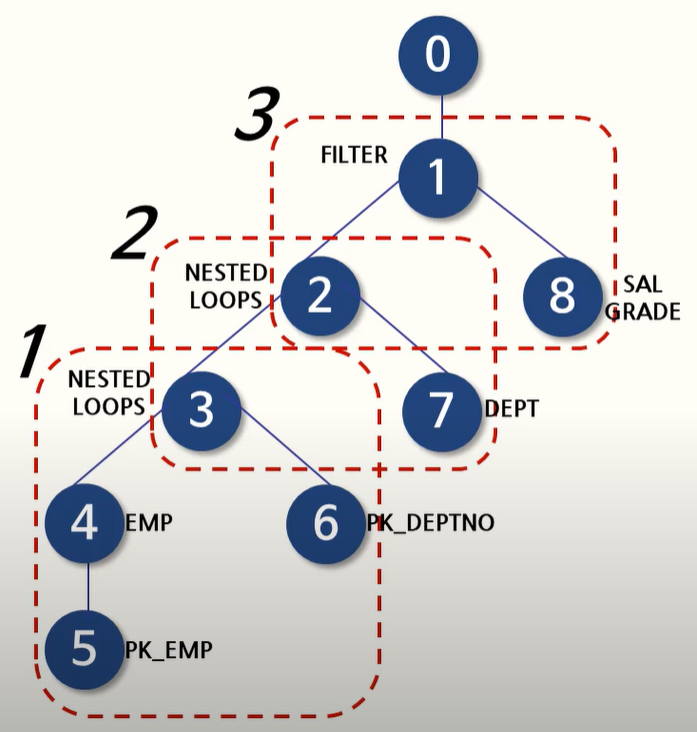
위의 예제를 기준으로 한다면 위와 같은 순서로 해석해나갑니다. 자식들의 좌측부터 차례대로 읽어주고 그 다음에 상위 부모로 올라가는 식으로 반복하시면 됩니다.
위의 예제는 5 -> 4 -> 6 -> 3 -> 7 -> 2 -> 8 -> 1 -> 0 순으로 진행되겠군요.

위의 실행 계획을 해석하자면 위의 그림과 같습니다.
5번 : PK_EMP 인덱스를 사용하여 INDEX RANGE SCAN을 하면서 조건에 만족하는 인덱스 블록과 키 값을 검색한 결과를 반환합니다.
4번 : 5번에서 읽은 ROWID를 기반으로 EMP 테이블로 이동하여 조건에 부합하는 결과를 반환합니다.
6번 : PK_DEPTNO 인덱스에서 INDEX UNIQUE SCAN 방식으로 검색한 결과의 ROWID를 반환합니다.
3번 : 4번과 6번에서 반환된 데이터들을 기준으로 NESTED LOOP JOIN 방식으로 4번에서 반환된 데이터의 숫자만큼 반복하여 조인한 결과를 반환합니다.
7번 : DEPT 테이블도 4번과 같이 조건에 부합하는 결과를 반환합니다.
2번 : NESTED LOOP JOIN 방식으로 3번과 같이 JOIN의 결과를 만들어줍니다.
8번 : SALGRADE 서브쿼리를 실행합니다.
1번 : 서브쿼리를 통해 해당 조건을 만족하는 데이터를 필터링하여 반환합니다.
SCAN 의 종류와 속도
실행 계획을 분석하기 위해서는 SCAN이라는 용어를 알고 있어야 합니다. SCAN이란, 말 그대로 데이터를 읽는 작업을 말하는데 SCAN을 수행하는 방식을 일컬어 접근 경로라고 합니다. 특히 아래 3가지 SCAN 방법을 아시는 것이 중요합니다.
FULL TABLE SCAN : 테이블의 전체 데이터를 읽어 조건에 맞는 데이터를 추출하는 방식 입니다.
ROWID SCAN : ROWID를 기준으로 데이터를 추출하며 단일 행에 접근하는 방식 중에서 가장 빠릅니다.
INDEX SCAN : 말 그대로 인덱스를 활용하여 원하는 데이터를 추출하는 방식입니다.
이 두 가지 SCAN 방법 중 개발자가 손쉽게 유도할 수 있는 SCAN의 방법은 FULL TABLE SCAN과 INDEX SCAN입니다. 이 중에서 테이블에 데이터가 많지 않아 INDEX를 타야 하는 시간 소요가 불필요하다고 느껴지거나 테이블에서 추출해야 하는 데이터 양이 엄청 많다면 FULL TABLE SCAN을 하는 것이 유리할 수 있고 반대로 많은 데이터가 있는 테이블에서 내가 원하는 데이터를 추출해야 하는 상황이라면 INDEX SCAN을 하는것이 좋습니다.
FULL TABLE SCAN을 타는 상황
1. 조건절에서 비교한 칼럼에 인덱스가 없는 경우
2. 조건절에서 비교한 컬럼에 최적화된 인덱스는 있지만 조건에 만족하는 데이터가 테이블의 많은 양을 차지하여 FULL TABLE SCAN이 낫다고 옵티마이저가 판단하는 경우
3. 인덱스는 있으나, 테이블의 데이터 자체가 적어 FULL TABLE SCAN이 낫다고 옵티마이저가 판단하는 상황
4. 테이블 생성 시 DEGREE 속성 값이 크게 설정되어 있는 경우
옵티마이저가 판단 후 TABLE FULL SCAN을 탄다면 그냥 두는 것이 좋고 INDEX SCAN이 더 유리한데도 불구하고 INDEX가 없어 부득이하게 FULL TABLE SCAN을 한다면 INDEX를 하나 만드는 것이 좋습니다. 물론 INDEX를 필요할 때마다 만드는 것도 UPDATE와, DELETE 등의 속도를 저해하기에 마냥 좋은 것은 아닙니다.
[Oracle] 오라클 인덱스(Index) 사용법 총정리(생성, 조회, 삭제, 리빌드)
ROWID SCAN을 타는 상황
1. 조건절에 ROWID를 직접 명시할 경우
2. INDEX SCAN을 통해 ROWID를 추출한 후 테이블에 접근할 경우
ROWID SCAN은 단일 행 접근이 매우 빠르기 때문에 ROWID SCAN가 유리하다고 판단되면서 ROWID SCAN을 탈 수 있는 상황이라면 유도해주는 것이 좋습니다.
INDEX SCAN을 타는 상황
| 인덱스 종류 | 상황 |
| INDEX UNIQUE SCAN | UNIQUE INDEX를 구성하는 모든 컬럼이 조건에 "="로 명시된 경우 |
| INDEX RANGE SCAN | 1. UNIQUE 성격의 결합 인덱스의 선두 컬럼이 WHERE절에 사용되는 경우 2. 일반 인덱스의 컬럼이 WHERE절에 존재하는 경우 |
| INDEX RANGE SCAN DESCENDING | INDEX RANGE SCAN을 수행함과 동시에 ORDER BY DESC절을 만족하는 경우 |
| INDEX SKIP SCAN | 1. 결합 인덱스의 선행 컬럼이 WHERE절는 경우 2. 옵티마이저가 INDEX SKIP SCAN이 FULL TABLE SCAN보다 낫다고 판단하는 경우 |
| INDEX FULL SCAN | 1. ORDER BY / GROUP BY의 모든 컬럼이 인덱스의 전체 또는 일부로 정의된 경우 2. 정렬이 필요한 명령에서 INDEX ENTRY를 순차적으로 읽는 방식으로 처리된 경우 |
| INDEX FULL SCAN DESCENDING | INDEX FULL SCAN을 수행함과 동시에 ORDER BY DESC절을 만족하는 경우 |
| INDEX FAST FULL SCAN | FULL TABLE SCAN을 하지 않고도 INDEX FAST FULL SCAN으로 원하는 데이터를 추출할 수 있고 추출된 데이터의 정렬이 필요 없으며 결합 인덱스를 구성하는 컬럼 중에 최소 한개 이상은 NOT NULL인 경우 |
| INDEX JOIN | 추출하고자 하는 데이터가 조인하는 인덱스에 모두 포함되어 있고 추출하는 데이터의 정렬이 필요없는 경우 |
'DB > Database Knowledge' 카테고리의 다른 글
| [DB] 데이터베이스 결합 인덱스에 대하여 (3) | 2021.07.14 |
|---|---|
| [DB] 데이터베이스 인덱스(Index) 란 무엇인가? (7) | 2021.07.04 |
| [DB] 데이터베이스 옵티마이저(Optimizer)에 대하여 (0) | 2021.06.23 |
| [DB기초] 트랜잭션이란 무엇인가? (5) | 2018.08.20 |