[DB] 파티션 테이블(Partition Table)이란 무엇인가?
파티션 테이블이란?
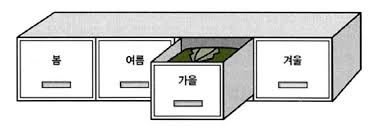
데이터베이스 테이블의 데이터들이 너무 많아서 어떤 데이터를 조회하려고 할 때 시간이 너무 많이 소요된다면 어떻게 해야 할까요? 이것을 개선할 수 있는 많은 방법이 있겠지만 파티션 테이블로 만드는 방법도 좋은 방법이 될 수 있습니다. 파티션 테이블은 논리적으로는 하나의 테이블이지만 물리적으로는 여러 개의 파티션으로 나뉘어 데이터들이 각각의 세그먼트에 저장되는 테이블이라고 생각하시면 됩니다. 파티션 테이블에는 Pruning이라는 기능이 있어서 특정 데이터를 조회를 할 때 그 데이터가 속해있는 세그먼트만 빠르게 조회할 수 있는 기능이 있습니다. 이 뿐만이 아니라 파티션 테이블은 논리적으로는 하나의 테이블이기 때문에 조회 쿼리문을 특별하게 지정해 줄 필요는 없지만 데이터들이 물리적으로 다른 세그먼트에 저장되기 때문에 개발과 관리 양쪽 측면에서 장점이 많습니다.
파티션 테이블의 장단점
장점
- Select Query Performance가 향상될 수 있다. (Table Full Scan이 필요한 조회 쿼리)
- 디스크 장애 시 해당 파티션만 영향을 받으므로 데이터의 훼손 가능성이 감소하고 가용성이 향상
- 개별 Partition 단위의 관리가 가능 (DML, Load, Import, Export, Exchange 등
- 논리적으로는 하나의 테이블이기 때문에 개발되어 있는 쿼리문을 변경할 필요가 없음
- 조인 시 파티션 간의 병렬 처리 및 파티션 내에서의 병렬 처리를 수행
- 데이터 액세스 범위를 줄여 성능을 향상하고 테이블의 파티션 단위로 디스크의 I/O를 분산해 부하를 감소
단점
- 파티션 키 값 변경에 대한 별도 관리 필요하기 때문에 관리가 불편하다.
- 파티션에 기준이 되는 것이 컬럼의 일부일 때 일부를 기준으로 파티션을 구성할 수 없으므로 이에 해당하는 오버헤드 컬럼이 있어야 함.
- 데이터를 입력받았을 때 연산 오버헤드가 발생하여 테이블에 Insert 되는 속도가 느려짐
- JOIN에 대한 비용이 증가함
어떤 테이블을 파티션 테이블로 만들어주면 좋을까?
모든 기법에는 장단점이 있듯 파티션 테이블은 JOIN에 대한 비용이 증가하고 데이터를 입력받았을 때 어디에 넣어야 하는지에 대한 연산 오버헤드가 발생하며 테이블과 인덱스를 따로 파티셔닝 할 수 없는 등의 단점들이 존재합니다. 그렇기 때문에 파티션 테이블은 데이터의 양이 많고 INSERT가 지속적으로 일어나는 테이블만 파티션 테이블로 지정해주는 것이 좋습니다. 예를 들자면 로그가 저장되는 테이블을 예로 들 수 있겠습니다. 로그 테이블의 특징은 지속적으로 테이블에 INSERT 되며 관리하고 있는 데이터들이 많다는 것입니다. 그리고 로그의 특성상 몇 달만 지나도 별로 쓸모없어지는 데이터들이 많습니다. 이를 월 단위나, 연단 위의 파티션 테이블로 파티셔닝(partitioning) 한다면 필요한 로그를 조회하는 속도도 빠르게 만들 수 있고 몇 년이 지나 더 이상 필요가 없어진 데이터들을 해당 파티션만 제거함으로써 보다 효율적으로 데이터 관리를 할 수 있겠습니다.
이 밖의 고려사항
- 일부 데이터가 손상되더라도 나머지 데이터 사용이 가능해야 하는 테이블
- DB 장애 시 복구를 최대한 빨리해야 하는 테이블
파티션 키 컬럼 (파티셔닝 키)
파티션 키 컬럼은 가장 많이 사용하는 Range Partition Table에서 물리적으로 테이블이 나뉘는 기준이 되는 컬럼으로 데이터가 어느 세그먼트에 들어갈 수 있는지 직관적으로 확인이 가능한 월(Month)이나 연(Year)이 있는 날짜(DT) 컬럼으로 많이 지정합니다. Range Partitioning에서의 Load Balancing은 파티션 키에 의존하므로 파티션 키 선정 시 이를 중요시 고려해야 합니다. 특히 여러 파티션에 대한 조회는 한 테이블로 구성하였을 경우보다 효율이 떨어집니다. 따라서 파티션으로 구성하려고 한다면 파티션의 기준이 되는 키를 잘 구성해야 합니다.
- Primary Key와 같이 데이터들의 구분이 지어지지 않는 컬럼은 피해야 한다.
- 데이터들이 어디에 들어가 있는지 직관적으로 판단이 가능한 컬럼(날짜 컬럼)
- I/O 병목을 줄일 수 있는 데이터 분포도가 양호한 컬럼
파티션의 숫자 결정
- 검색조건에서 Composite Primary Key의 일부분만을 사용할 경우 Partition의 개수가 적은 것이 속도가 빠름
- Composite Primary Key의 전체를 사용할 경우는 Partition의 개수가 많은 것이 속도가 빠름
- Batch, OLAP 작업일 경우는 partition 개수가 적은 쪽이 OLTP작업의 경우는 Partition 개수가 많은 것이 Performance가 더 우수
- 실제 테이블을 구성함에 있어 Partition의 개수가 너무 적을 경우 Partition 효과를 볼 수 없게 되고 너무 많을 경우 각 Partition의 value range를 체크하므로 parsing time이 길어지고 관리대상이 많아지는 단점이 존재
파티션 테이블의 종류
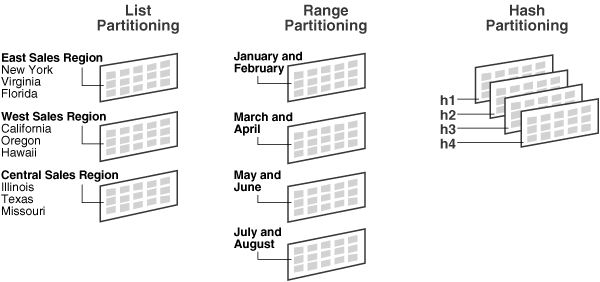
Range Partitioning
- 일, 월, 분기 등 특정 컬럼의 정렬 값을 기준으로 분할하는 방식으로 논리적인 범위의 분산에 효율적
- 관리가 용이하며 이력 데이터에 적합
- 파티션을 결정하는 컬럼을 명시하여야 하며 MAXVALUE값은 NULL값을 포함
- 범위가 포함하는 데이터의 양이 일정하지 않은 경우 특정 파티션에 대해 데이터가 편중될 수 있음
Hash Partitioning
- 데이터의 균등 분할을 통해 성능을 향상하고자 하는 경우에 효율적
- 파티션 키에 해시함수를 적용한 결과 값이 같은 레코드를 같은 파티션 세그먼트에 저장해 두는 방식 - Row와 파티션 간의 매핑을 사용자가 제어할 수 없음
- 파티션 키의 해시 값에 의해 데이터가 다수의 파티션에 분배되며 균등한 분배를 위해서는 파티션 개수를 명시하여야 하며 파티션의 수는 2의 거듭제곱의 수로 지정
- NULL값은 첫 번째 파티션에 위치함
- 고객 ID처럼 변별력이 좋고 데이터 분포가 고른 컬럼을 파티션 키 컬럼으로 선정해야 효과적
List Partitioning
- 파티션 컬럼을 명시, 키 컬럼 값을 기준으로 파티션 하는 방식 컬럼의 구체적인 값들에 대해 파티션을 명확하게 컨트롤하고자 할 때 효율적
- 연관되지 않은 데이터, 순서에 맞지 않는 데이터의 그루핑을 쉽게 할 수 있음
- 명시되지 않은 값을 가진 Row는 Insert가 불가능
- 여러 컬럼으로 파티션 키를 생성할 수 없고 오직 하나의 컬럼만 가능
- 각 파티션에 대해 모든 파티션 키는 반드시 문자로 LIST 되어야 하며 파티션 값의 List는 4K까지 가능
- 파티션 키의 값은 64K-1을 초과할 수 없고 NULL 값을 포함한 어떠한 값이라도 한 번만 명시 가능
※ Range -> Hash -> List 순으로 많이 사용한다.
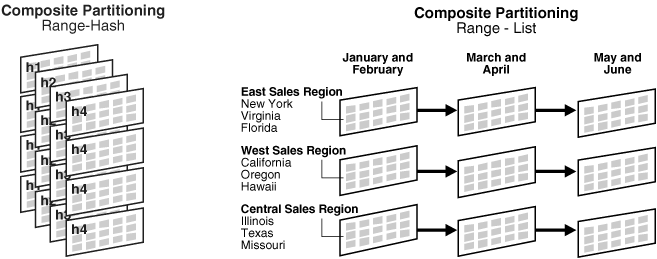
Composite Partitioning
- Range + List, Range + Hash 파티션 등의 조합으로 구성하며 주 파티션과 서브파티션으로 이루어짐
- 이력 데이터와 온라인 데이터의 복합적인 성격을 지닌 데이터의 분할에 용이하며 병렬 DML 작업에 뛰어난 수행성능을 보장
- 파티션 및 서브 파티션 단위의 관리 작업 수행이 가능
- Hash 파티셔닝의 경우 스토리지 스트라이핑으로 인해 디스크 점핑이 발생할 수 있으므로 충분한 검토 후 적용
- 단 이렇게 구성할 경우 파티션을 나누는 기준이 두개가 되기 때문에 파티션의 갯수가 너무 많아지게 됨 (주 파티션의 갯수 X 서브파티션의 갯수) 인덱스의 경합이 너무 심해져서 잘 사용하지는 않음
※ 파티션 테이블의 생성 방법을 알고 싶다면 아래 글을 참고해주세요
[Oracle] 오라클 파티션 테이블 사용법 (생성, 조회, 수정, 삭제)
[Oracle] 오라클 파티션 테이블 사용법 (생성, 조회, 수정, 삭제)
파티션 테이블이란? 파티션이란 테이블에 있는 특정 컬럼값을 기준으로 데이터를 분할해 저장해놓은 테이블입니다. 이때 논리적인 테이블은 1개이지만 물리적으로는 분할한 만큼 파티션이 만
coding-factory.tistory.com