NESTED LOOP JOIN이란?
줄여서 NL JOIN이라고도 불리는 NESTED LOOP JOIN은 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결합하여 원하는 결과를 조합하는 조인 방식입니다. 조인해야 할 데이터가 많지 않은 경우에 유용하게 사용됩니다. NESTED LOOP JOIN은 드라이빙 테이블로 한 테이블을 선정하고 이 테이블로부터 where절에 정의된 검색 조건을 만족하는 데이터들을 걸러낸 후, 이 값을 가지고 조인 대상 테이블을 반복적으로 검색하면서 조인 조건을 만족하는 최종 결과값을 얻어냅니다.
Driving Table 과 Driven Table
Driving Table이란 JOIN을 할 때 먼저 액세스 되어 ACCESS PATH를 주도하는 테이블을 Driving Table이라고 합니다. 즉, 조인을 할때 먼저 액세스 되는 테이블을 Driving Table이라고 하며 나중에 액세스 되는 테이블을 Driven Table이라고 합니다. 여기서 Driving Table은 옵티마이저가 결정하고 자연스레 Driving Table이 아닌 테이블은 Driven Table로 결정됩니다.
학생 테이블과 학교 테이블로 예를 들면 이름이 홍길동인 학생의 학교 정보를 알고 싶다면 학생 테이블이 Driving Table이 되는 것이고 서울대학교의 학생들의 정보를 보고 싶다면 학교 테이블이 Driving Table이 되는 것입니다.
NESTED LOOPS JOIN의 장단점
1. 인덱스에 의한 랜덤 액세스에 기반하고 있기 때문에 대량의 데이터 처리 시 적합하지 않습니다.
2. Driving Table로는 데이터가 적거나 where절 조건으로 row의 숫자를 줄일 수 있는 테이블이어야 합니다.
3. Driven Table에는 조인을 위한 적절한 인덱스가 생성되어 있어야 합니다.
4. 선행 테이블의 결과를 통해 후행 테이블을 액세스 할 때 랜덤 I/O가 발생합니다.
NESTED LOOP JOIN의 동작 방식
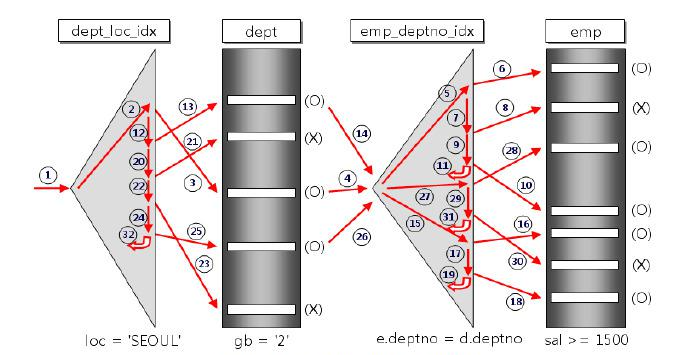
NESTED LOOP JOIN의 동작 방식은 위의 그림과 같고 동작 순서는 번호 순대로 진행됩니다.
for(i=0; i<dept.length; i++) { -- driving table
for(j=0; j<emp.length; j++) { -- driven table
// Search
}
}동작 순서를 보시면 아시겠지만 위와 같은 이중 for문과 작동원리는 비슷합니다.
위의 그림에서 먼저 액세스 된 dept Table이 Driving Table이고 나중에 액세스 된 emp Table이 Driven Table입니다. 위의 그림에서 볼 수 있듯이 dept의 데이터를 추출하기 위해 dept_loc_idx라는 인덱스를 사용하여 gb = '2'인 데이터를 추출하였으며, 이렇게 검색된 데이터를 가지고 같은 deptno를 가지는 사원들의 정보를 emp_deptno_idx라는 인덱스를 사용하여 sal >=1500 조건으로 emp Table을 조회하였습니다.
이렇듯 NESTED LOOP JOIN의 동작 방식은 Driving Table의 처리 범위를 하나씩 액세스 하면서 추출된 값으로 Driven Table을 조인하는 방식으로 동작하게 됩니다.
NESTED LOOP JOIN의 성능 개선 포인트
적절한 드라이빙 테이블의 선정
NESTED LOOP JOIN을 할때는 어떤 테이블이 먼저 액세스 되느냐에 따라서 속도의 차이가 크게 날 수 있습니다. 앞서 NESTED LOOP JOIN 동작 과정에서 살펴보았듯이 먼저 액세스 되는 Driving Table의 조건을 만족하는 결과 row수가 많다면 그만큼 반복해서 Driven Table에 접근해야 하므로 성능은 자연히 나빠질 것입니다. 따라서 NESTED LOOP JOIN방식을 채택하였다면 Driving Table의 선택이 매우 중요합니다. 그렇기에 Driving Table은 WHERE 절로 최대한의 데이터를 거를 수 있는 테이블이나 애초에 데이터의 양이 적은 테이블로 선정하는 것이 좋습니다.
드라이빙 테이블 유도 방법
1. 힌트의 사용
/*+ORDERED*/ -- FROM절에 기술한 테이블 순서대로 제어
/*+LEADING (table명)*/ -- 힌트 내에 제시된 테이블이 드라이빙으로 처리됨
가장 쉬운 방법은 위와 같이 힌트를 사용하는 방법입니다. 위의 두가지 힌트 중 하나를 사용하시면 됩니다. 만약 위의 두가지 힌트를 동시에 사용하게 되면 LEADING 힌트는 적용되지 않습니다.
2. 뷰를 사용한다.
뷰를 통해서 데이터를 먼저 읽어낼 수 있고 뷰로 데이터를 읽은 결과로 다음 테이블로 연결을 시도한다면 조인 순서를 제어할 수 있습니다.
Driven Table의 조인 컬럼에 인덱스 존재 유무
Driven Table의 조인 조건으로 사용될 칼럼에 인덱스가 존재하는지 여부도 성능에 매우 큰 영향을 줍니다. Driven Table에 인덱스가 존재하지 않는다면 Driving Table에서 도출된 결과와 맞는지를 FULL TABLE SCAN으로 일일이 비교해야 하기 때문입니다. Driven Table의 Join 컬럼에 인덱스가 생성되지 않았다면 인덱스 생성을 고려해 보는 것이 좋고 그것이 어렵다면 조인 방식을 SORT / MERGE 방식등 다른 방식으로 바꾸는것이 성능 향상에 도움이 됩니다.
인덱스에 대해 궁금하시다면 아래의 글을 참고해주세요.
'DB > Database Knowledge' 카테고리의 다른 글
| [DB] 데이터베이스 HASH JOIN (해시 조인)에 대하여 (0) | 2021.07.17 |
|---|---|
| [DB] 데이터베이스 SORT MERGE JOIN (정렬 병합 조인)에 대하여 (0) | 2021.07.16 |
| [DB] 데이터베이스 결합 인덱스에 대하여 (3) | 2021.07.14 |
| [DB] 데이터베이스 인덱스(Index) 란 무엇인가? (7) | 2021.07.04 |